이 글의 요약
- 산점도에서 상관계수가 0이라는 것은 두 변수 사이에 직선관계가 약한 것을 의미하는 것이지 아무 관계가 없다는 의미가 아니다.
- 이상값은 무조건 제거하고 분석한다는 것은 오답이다.
- 결측값(Missing Value)이란 데이터 수집 과정에서 측정되지 않거나 누락된 데이터를 말한다.
- plyr 함수 중 입력데이터는 리스트이고, 출력데이터는 데이터프레임인 plyr인 함수는 ? = ldply


목차
R기초, 벡터, 상자그림, 이상값
- R에서 벡터는 하나 또는 하나 이상의 스칼라 원소들을 갖는 집합이다.
- 합치는 벡터에 수치형과 문자형이 결합하면 문자형이 우선한다.
- 논리연산자 벡터를 숫자형 벡터처럼 사용하는 경우 자동적으로 'TRUE'는 1 값을 갖는다.
- R은 대소문자를 구분한다.
벡터의 연산
두 벡터의 원소의 갯수가 다르더라도 연산과정에서 원소의 개수가 적은 쪽의 벡터는 원소 갯수가 많은 쪽의 벡터와 동일하게 원소의 개수를 맞춘다.
x<-c(1,2,3), y<-c(1,2,3,4,5,6)
x+y의 값은 (2,4,6,5,7,9)
벡터, 행렬, 배열은 한 가지 유형 데이터 타입의 구조만 가능하다.
리스트, 데이터 프레임, 데이터 테이블은 각 열이 서로 다른 타입의 데이터 구조가 가능하다.
- NA = R 에서 데이터 결측값
- NaN = 수학적으로 불가능한 수를 표시
- NULL = 데이터 유형과 자료의 길이가 0인 비어 있는 값
R 의 대표 함수
summary() 함수는 최솟값, 1사분위수, 중위수, 3사분위수, 최댓값, 평균값을 구할 수 있다.
set.seet() 함수는 난수 발생 시 동일한 난수가 발생되도록 초기화한다.
R 그래픽 기능
산점도(상관분석의 적용을 위해 사용)의 특징
- 선형 또는 비선형 관계의 여부
- 이상점의 존재 여부
- 자료의 층화 여부
원점의 통과 여부
산점도에서 상관계수가 0이라는 것은 두 변수 사이에 직선관계가 약한 것을 의미하는 것이지 아무 관계가 없다는 의미가 아니다.
R의 유용한 기능

1) paste() 함수는 우리가 정의한 벡터의 원소에 무언가를 붙이거나 벡터의 원소를 하나로 합쳐주는 기능이다.
number<-1:5
alphabet<-c("A", "B", "C")
paste(number, alphabet)
[1] "1 A" "2 B" "3 C" "4 D" "5 E"
paste(number, alphabet, sep="to the")
[1] "1 to the A" "2 to the B" "3 to the C" "4 to the D" "5 to the E"
'sep='옵션을 통해 붙이고자 하는 문자열들 사이에 구분자 역할을 한다.
2) substr(x, start, stop) 함수는 문자형 벡터 x의 start 에서부터 stop 까지만 잘라오는 것이다.
country<-c("Korea", "Japan")
substr(country,1,3)
[1] "Kor" "Jap"
3)strsplit(x, split=",") 함수는 문자형 벡터 x를 split 기준으로 해서 나누기
nation<-c("Korea,Seoul", "Japan,Tokyo")
nation_split<-strsplit(nation, split=",")
nation_split
[[1]]
[1] "Korea" "Seoul"
[[2]]
[1] "Japan" "Tokyo"
4) R에는 4가지 정규분포 관련 함수가 있다.
rnorm() 함수는 정규분포를 따르는 난수를 생성하는데에 사용한다.
dnorm() 함수는 정규분포의 확률밀도함수를 계산하는데에 사용한다.
pnorm() 함수는 표준정규분포의 누적분포함수를 계산하는데에 사용한다.
qnorm() 함수는 표준정규분포의 분위수를 계산한다.
5) 자료형 데이터 구조 변환
as.integer(3.14)
[1] 3
as.numeric("foo")
[1] NA
as.numeric(FALSE)
[1] 0
as.numeric(TRUE)
[1] 1
as.logical(0.45)
[1] TRUE
as.Date('01/13/2018", format"%m%d%Y")
[1] "2018-01-13"
대푯값의 비교(평균, 중위수, 최빈수)

- 왼쪽 꼬리를 갖는 분포(우측 비대칭, 왜도 < 0) : 평균 < 중위수 < 최빈수
- 좌우 대칭인 분포(왜도 = 0) : 평균 = 중위수 = 최빈수
- 오른쪽 꼬리를 갖는 분포(좌측 비대칭, 왜도 > 0) : 최빈수 < 중위수 < 평균
boxplot(상자그림)

- IQR(사분위수범위) = Q3(3사분위수)-Q1(1사분위수)
- IQR의 크기가 클 수록 분산이 크다는 것을 의미한다.
- 최솟값 = Q1 - 1.5*IQR
- 최댓값 = Q3 + 1.5*IQR
- Q2(2사분위수) 의 위치에 따라 데이터의 비대칭도 확인 가능
- 이상치검색 가능 - 데이터에 NA가 있어도 실행이 되는 시각화 함수
- 범위 = 최댓값 - 최솟값
- 왜도 : 정규분포이면 왜도는 0, 0보다 크면 왼쪽으로 치우친 분포
- 첨도 : 첨도가 3보다 크면 정규분포보다 뾰족한 모양
이상값(특이값 = Outlier)
- 이상값이란 보통 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 큰 값을 말한다.
- 이상값은 상자그림에서 Q1 또는 Q3 로부터 1.5*IQR 에서 관측된 값이다.
- 이상값과 관련된 알고리즘은 ESD, MADM, boxplot, summary 함수 등을 이용한다.
- ESD알고리즘은 평균으로부터 3*표준편차만큼 떨어져 있는 값들을 이상값으로 판단한다.
- 부정사용방지 시스템이나 부도예측시스템에서는 이상값은 의미가 있으므로 무조건 제거하지는 않는다.
- ESD알고리즘에서 이상값은 무조건 제거하고 분석한다는 것은 오답이다.
결측값, 결측값의 대치법
결측값(Missing Value)이란 데이터 수집 과정에서 측정되지 않거나 누락된 데이터를 말한다.
결측값의 처리
1) is.na() 함수는 NA값을 조사해 논리값으로 반환한다(NA=TRUE).
2) complete.cases() 함수는 NA값을 조사해 논리값으로 반환한다(NA=FALSE).
3) 특정값을 결측 처리하는 방법 = iris[iris$sepal.length==4.0]<- NA #특정값 4.0을 NA처리한다.
4) 데이터 프레임에서 결측값만 선택 또는 삭제하기
iris_na<-iris
iris_na[c(10,20,30),3]<-NA
iris 3번째 변수 Petal.Length의 10,20,30번째 행을 NA(결측처리)
iris_na[!complete.cases(iris_na),] #NA(결측) 행만 추출 ★
iris_na[complete.cases(iris_na),] #NA(결측) 제외한 행 추출 ★
5) na.omit() #NA가 있는 행 전체 삭제
6) na.rm=TRUE #NA값이 있으면 해당 결측값을 제외하고 함수가 적용된다.
통계 방법론 - 결측값의 대치법
단순 대치법
1) 완전 분석법은 불완전 자료를 모두 무시하고 완전하게 관측된 자료만으로 표준적 통계기법에 따라 분석하는 방법이다.
2) 평균 대치법은 자료의 적절한 평균값으로 결측값을 대치해서 불완전한 자료를 완전한 자료로 만든 후, 완전한 자료를 마치 관측 또는 실험되어 얻어진 자료라 생각하고 분석하는 방법이다. 이는 통계량의 표준오차가 과소 추정되는 문제가 있다.
3) 단순 확률 대치법은 평균 대치법에서 관측된 자료를 토대로 어떤 적절한 확률 값을 부여한 후 대치하는 방법이다. 이는 평균 대치법의 문제를 보완하지만 대부분의 경우에 추정량의 표준오차 계산 자체가 어려운 문제가 있다.
- Cold-deck : 이전 자료를 사용(다른 자료를 사용해 결측치를 대체)
- Hot-deck : 대체군 내에서 응답값 중 하나를 랜덤하게 선정(동일한 자료에서 결측치를 대체)
- Regression : 보조변수를 이용하여 회귀 예측치를 대체
- Nearest Neighbour : 보조변수를 이용하여 무응답조사 단위와 가장 유사한 응답 조사단위를 찾아 대응되는 항목값으로 대체
다중 대치법
다중 대치법은 단순 대치법처럼 한 번만 하는게 아니라 n번의 대치를 통한 n개의 가상적인 완전한 자료를 만들어서 분석하는 방법이고 대치, 분석, 결합 단계로 구성되어 있다.
reshape패키지, plyr패키지, sqldf패키지
데이터 마트란 데이터의 한 부분으로서 특정 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터웨어하우스이다.
reshape 패키지
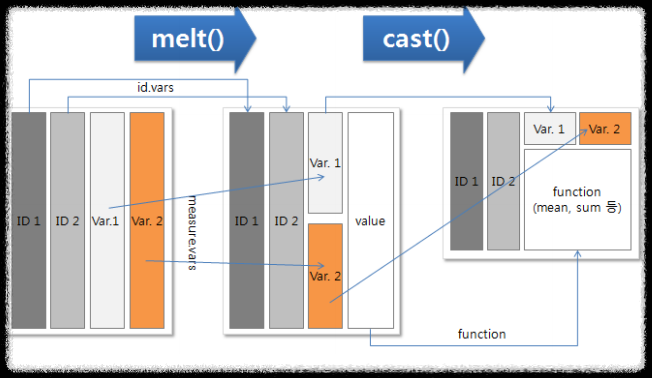
reshape 패키지는 melt와 cast 함수만을 사용하여 데이터를 재구성하거나 밀집화된 데이터를 유연하게 생성해준다.
melt 함수는 그룹별로 mean, sum 요약이 불가능한 명령어이다.

reshape 패키지는 데이터의 모양을 바꾸거나 그룹별 요약값을 계산하는 함수들을 담고 있다.
plyr 패키지
- plyr 패키지는 데이터를 분리하고(split), 분할된 데이터에 특정 함수를 적용(apply), 결과를 재결합(combine) 처리하는 함수를 제공한다.
- apply 함수와 multi-core 사용 함수를 이용하면 for loop 을 사용하지 않고 매우 간단하고 빠르게 처리한다.
- plyr 패키지는 apply 함수에 기반한 데이터와 출력변수를 동시에 배열로 치환하여 처리한다.
- plyr 패키지는 앞에 두 개의 문자를 접두사로 가지는데, 첫 번째 문자는 입력하는 데이터 형태를 나타내고, 두 번째 문자는 출력하는 데이터 형태를 나타낸다.
- 데이터처리 함수 형식 = (입력데이터)(출력데이터)ply 5글자의 함수명으로 이름이 지어진다.

plyr 함수 중 입력데이터는 리스트이고, 출력데이터는 데이터프레임인 plyr인 함수는 ? = ldply
sqldf 패키지는 SQL문을 사용할 줄 아는 사용자가 쉽게 데이터를 접근할 수 있게 해준다.
자료의 척도
- 명목척도는 중앙값 또는 평균값 계산이 가능하다는 것은 오답 보기이다.
- 구간척도는 측정 대상이 갖고 있는 속성의 질을 측정한다는 것은 오답 보기이다(질->양).
- 구간척도는 절대 영점이 존재한다는 것은 오답 보기이다.
참고자료 : ADsP한권으로끝내기(김계철 지음)
<함께보면 좋은 글>
ADsP(데이터분석 준전문가) 자격 안내, 시험 일정, 공부 방법
이 글의 요약ADsP(데이터분석 준전문가) 란 데이터 이해에 대한 기본지식을 바탕으로 데이터분석 기획 및 데이터분석 등의 직무를 수행하는 실무자이다.시험과목은 데이터 이해, 데이터분석 기
jomosi.tistory.com
ADsP(데이터분석 준전문가) 1과목 데이터 이해 시험 요약 공부
이 글의 요약데이터, 정보, 지식을 통해 최종적으로 지혜를 얻어내는 과정을 피라미드 형태로 나타낸 것이 DIKW 피라미드이다. 예시로는 데이터(Data)는 A마트의 연필 가격은 100원, B마트의 연필 가
jomosi.tistory.com
ADsP(데이터분석 준전문가) 1과목 데이터 이해 시험 요약 공부 - 빅데이터, 개인정보, 데이터 3법
이 글의 요약빅데이터는 없었던 것이 새로 등장한 것이 아니라 기존의 데이터, 처리방식, 다루는 사람과 조직 차원에서 일어나는 변화를 의미함. 빅데이터 시대의 위기 요인에는 사생활 침해,
jomosi.tistory.com
ADsP(데이터분석 준전문가) 1과목 데이터 이해 시험 요약 공부 - 데이터 사이언티스트, ETL, 하둡
이 글의 요약데이터 사이언티스트가 갖춰야 할 역량(가트너) 4가지는 데이터 관리(데이터에 대한 이해), 분석 모델링(분석론에 대한 지식), 비즈니스 분석(비즈니스 요소에 초점), 소프트 기능(커
jomosi.tistory.com
ADsP(데이터분석 준전문가) 2과목 데이터 분석 기획 시험 요약 공부 - 분석 주제 유형, KDD분석방법
이 글의 요약분석 방법론의 구성 요소 4가지 : 상세한 절차(Procedure), 방법(Methods), 도구와 기법(Tools & Techniques), 템플릿과 산출물(Templates & Outputs) KDD(Knowledge Discovery in Database)는 1996년 Fayyad가 체계적
jomosi.tistory.com
ADsP(데이터분석 준전문가) 2과목 데이터 분석 기획 시험 요약 공부 - 애자일모델, 워터폴모델, 분
이 글의 요약 상향식 접근 방식 이란 문제의 정의 자체가 어려울 경우 데이터를 기반으로 문제의 재정의 및 해결방안을 탐색하고 이를 지속적으로 개선하는 방식이다. - Diverse(발산), 애자일 모
jomosi.tistory.com
ADsP(데이터분석 준전문가) 2과목 데이터 분석 기획 시험 요약 공부 - 분석 마스터플랜, 분석 거버
이 글의 요약반복적인 분석 체계는 모든 단계를 반복하기보다 데이터 수집 및 확보와 분석 데이터를 준비하는 단계를 순차적으로 진행하고, 모델링 단계는 반복적으로 수행하는 혼합형을 많이
jomosi.tistory.com
ENA, ENA PLAY, ENA DRAMA 편성표 및 채널번호
ENA 채널은 Entertainment DNA 의 약자로 KT 그룹 계열사인 skyTV(스카이라이프) 가 운영하는 채널입니다. ENA 외에 ENA PLAY, ENA DRAMA, ENA STORY 등 다양한 채널을 주제에 맞게 방영하고 있으며 최근에는 오은
jomosi.tistory.com
알바천국 이력서 양식 다운
▼아르바이트 이력서 양식 다운로드(doc 파일, hwp 파일)▼ 아래에서 자세히 확인하세요▼ 알바천국, 알바몬, 사람인, 잡코리아 등 인력 채용 플랫폼이 경쟁하며 시장에서 활발하게 활동하고 있습
jomosi.tistory.com
트위터 아이디 찾기
이 글의 요약 회원가입을 한 후에 이메일을 입력한 후 "이미 등록된 이메일입니다." 라는 문구가 뜨면 해당 이메일 주소로 트위터 아이디 찾기 새로운 이메일로 회원가입을 한 후에 @twittersupport
jomosi.tistory.com